What Is Survey Sampling?
Sometimes, a researcher may feel the need to survey as many people as possible and conducts a “census study”. Although this method seems easy, it is not applicable and efficient most of the time. It can also skew survey results. To reach your audience, try using some statistical tools rather than casting a net on the total population. This is “sampling”.
The goal of sampling is to save money and the amount of work it would take to survey the entire target population. Since all further analysis is based on the gathered data, it is necessary to select the samples carefully. As a general rule in sampling, one should consider the following:
- All individuals must have an equal chance of selection
- Sample sets must be representative of the entire target population
Different Methods of Sampling
There are many different ways of obtaining a sample. However, it is possible to classify methods into two different categories according to their statistical nature. These methods can be classified as either “probability” or “non-probability”.
Probability Sampling Methods
- Random sampling. This is the most basic and natural probability sampling method where every member of the entire population has an equal chance of selection. In the case of huge target populations, it is often hard or impossible to identify all the members of the population, so the pool of available subjects becomes biased.
- Systematic sampling. This easy probability sampling method selects every Nth member from a list of the entire population.
- Stratified sampling. This method is superior to random and systematic sampling due to less error. Stratified sampling involves the use of a subset (stratum) of the target population in which the members share one or more common characteristics. As an illustration, the stratum might be gender, job title, marital status, etc. Then, a basic probability method like random sampling may apply in order to select the required number of subjects from each stratum.
Non-probability Sampling:
- Convenience sampling. Its name makes it clear: this method is used out of convenience, choosing participants that are easily reachable. Convenience sampling is mostly used in preliminary research efforts in order to achieve an estimation of results without devoting much money and time to gain a random sample.
- Judgment sampling. This method is a common non-probability sampling method in which the researcher decides which members of the entire population should be selected based on his/her judgment. Since the researcher’s judgment is the criteria for selecting the sample, it is necessary to ensure that the selected sample is an appropriate representative of the entire target population.
- Quota sampling. This popular method is the non-probability version of the stratified sampling (i.e. the researcher determines the stratums first, then one of the non-probability methods like convenience or judgment sampling is applied). The difference between quota sampling and stratified sampling is that the randomness is not included in the former.
- Snowball sampling. This method relies on referrals from a small selected group of the target population to recruit additional members of the entire target population. This method may increase bias by reducing the probability of obtaining sufficient representativeness.
Read more: 8 Types of Survey Sampling + Pros & Cons, Errors & Bias, and More.
Pitfalls of Sampling
Non-coverage and frame problems impact probability sampling. As an illustration, considering the online survey system. It’s possible that everyone in the target population doesn’t have access to the internet in order to respond (non-coverage). Or, perhaps there’s a lack of contact information (e.g. email address) which leads to the frame problem. Both non-coverage and frame problems have a big influence on data quality. So, always report them when publishing the survey results.
Considering online surveys, researchers commonly publish surveys by sharing the URL link on different media, or simply by publishing it on their own websites in order to overcome the frame problem. However, this leads to sample selection bias which is almost out of the research control and get rise to the non-probability samples.
The standard statistical inference methods like confidence interval calculation and hypothesis test require a probability sample to be efficient and they may not return reliable results in case of applying directly on non-probability samples.
However the actual survey practices, e.g. in marketing research and opinion polling in particular, tremendously neglect the principle of probability sampling. So, consult with a professional sampling statistician to specify the condition that non-probability sampling may work correctly.
Sample Size Determination
From the sampling point of view, it is important to have a large enough population to minimize the sampling error. You can reduce sampling error by increasing the sample size or decreasing the random error in the data collection process. There are theoretical backgrounds and presentations for sample size estimation methods that are out of scope of this article. However, one can use the following simple formula in order to determine the required needed sample size.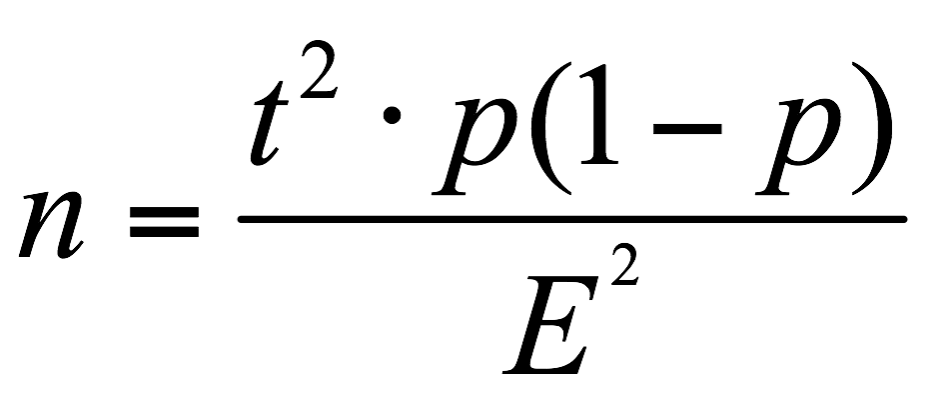
Where t is the confidence level (at 95% it is equal to 1.96), p is the estimation of the proportion and m is the margin of error.
The margin of error is a statistic describing the amount of random sampling error in a survey’s results. As an example, suppose the margin error is 2% and from all respondents, 59% picked an answer. Ask the same question to the entire target population and 57-61% would have picked the same answer.
Need to bring the size of the entire target population into account? Use this adjusted formula to determine the sample size: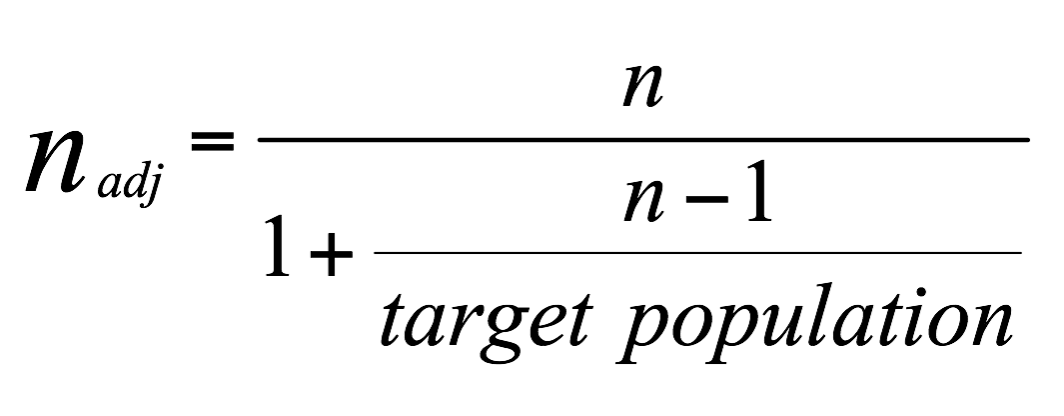
Conclusion
Ultimately, it doesn’t matter how carefully and efficiently a survey is designed. If the sampling and data gathering process is not done adequately, the results can be inaccurate and unreliable. Want to conduct an online survey with a company that provides robust analytics that can help inform your decisions? Get started for free with SurveyLegend!
Frequently Asked Questions (FAQs)
What is survey sampling?Survey sampling is the use of statistical tools to target a specific audience rather than casting a net on the total population.
Probability sampling and non-probability sampling.
Random sampling, systematic sampling, and stratified sampling.
Convenience sampling, judgment sampling, quote sampling, and snowball sampling.